People Analytics Case Study
Introduction
HR Analytica team requires a separate analytical view using a single SQL script for data assets, specifically focusing on individual employee deep dives. Our objective is to provide a holistic view of each employee's journey within the company, encompassing various facets such as:
- Employment history ordered by effective date, including salary, department, manager, and title changes.
- Calculation of previous historic pay rise percentages and value changes.
- Previous position and department history in months with start and end dates.
- Comparison of an employee’s current salary, total company tenure, department, position, and gender to the average benchmarks for their current position.
This comprehensive analysis is facilitated through three main components:
- Data Exploration: including the utilization of materialized views.
- Problem-solving: Innovative solutions tailored to address specific challenges.
- Visualization: Utilizing Tableau for intuitive presentation of insights.
Special thanks to Data with Danny by Danny Ma for providing both data resources and visualization ideas for this project.
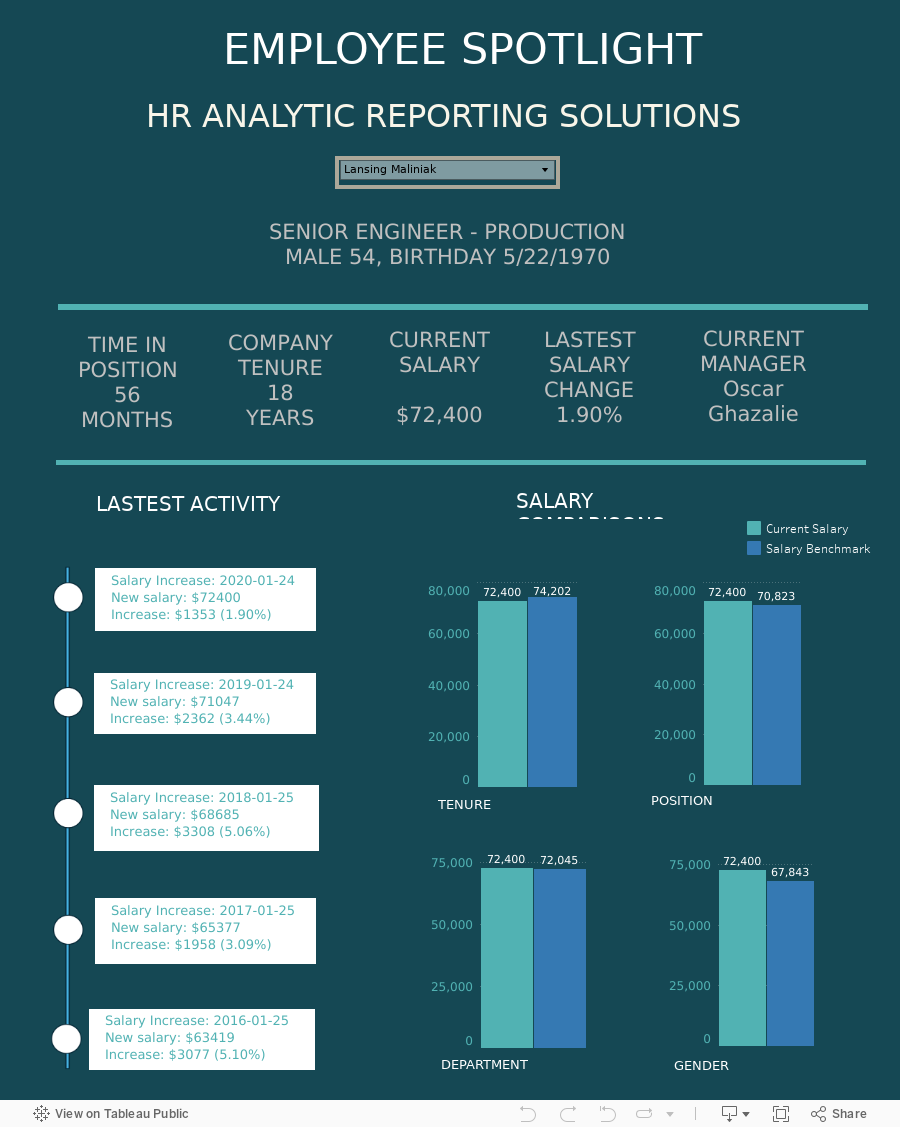
Table of contents
1. Data Overview - Exploration 🕵️♂️
1.1 Entity Diagram Relationship 🔗
1.2 Data Exploration 🔍
1.3 Updates MATERIALIZED VIEW 🔄
2. Problem Solving 💡
2.1 Solution for the Case Study 💡
2.2 Results 📊
3. Visualization on Tableau 📈
1. Data Overview - Exploration 🕵️♂️
1.1 Entity Diagram Relationship 🔗
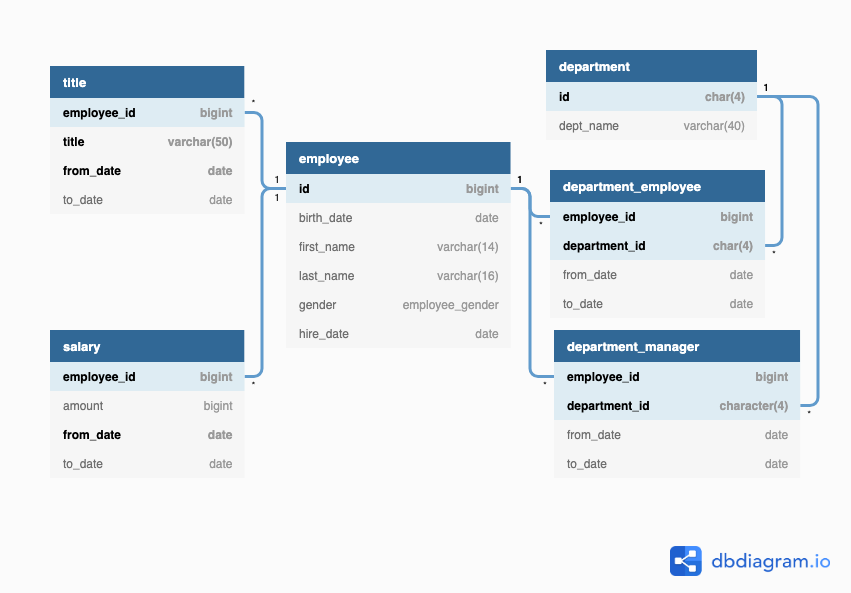
Before directly addressing the business requirements with solutions, it's essential to first examine the data using Entity-Relationship Diagrams (ERDs). These diagrams will help reveal various relationships among the tables. The EDRs for these datasets are displayed as follows:
1.2 Data Exploration 🔍
This case study is provided with 6 key datasets:
⭐ Employee table
In the employee table, each row uniquely represents the personal information of an employee, with the 'id' column serving as the primary key. Additionally, there is a problem concerning the date entries; the years have been mistakenly recorded as 18 years earlier than they should be.
-- Employees table SELECT * FROM employees.employee LIMIT 5;
Results:
| id | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02T00:00:00.000Z | Georgi | Facello | M | 1986-06-26T00:00:00.000Z |
| 10002 | 1964-06-02T00:00:00.000Z | Bezalel | Simmel | F | 1985-11-21T00:00:00.000Z |
| 10003 | 1959-12-03T00:00:00.000Z | Parto | Bamford | M | 1986-08-28T00:00:00.000Z |
| 10004 | 1954-05-01T00:00:00.000Z | Chirstian | Koblick | M | 1986-12-01T00:00:00.000Z |
| 10005 | 1955-01-21T00:00:00.000Z | Kyoichi | Maliniak | M | 1989-09-12T00:00:00.000Z |
⭐ Title
Our second table is the employees.title table which contains the employee_id which we can join back to our employees.employee table.
-- Employee IDs SELECT employee_id, COUNT(employee_id) AS id_count FROM employees.title GROUP BY employee_id ORDER BY id_count DESC LIMIT 5;
Results:
| employee_id | id_count |
|---|---|
| 10451 | 3 |
| 10009 | 3 |
| 10066 | 3 |
| 10258 | 3 |
| 10571 | 3 |
After inspecting the data - we notice that there is in fact a many-to-one relationship between the employees.title and employees.employee tables.
SELECT * FROM employees.title WHERE employee_id = 10005 ORDER BY from_date;
Result:
| employee_id | title | from_date | to_date |
|---|---|---|---|
| 10005 | Staff | 1989-09-12T00:00:00.000Z | 1996-09-12T00:00:00.000Z |
| 10005 | Senior Staff | 1996-09-12T00:00:00.000Z | 9999-01-01T00:00:00.000Z |
For our example, employee_id = 10005 Kyoichi Maliniak’s title was originally “Staff” from 1989-09-12 to 1996-09-12 when he was then promoted to “Senior Staff” which is his current position until the “arbitrary” end date of 9999-01-01 in our dataset.
Also, there is the issue with the dates where the year was wrongly input which is similar with the employee table above.
⭐ Salary
SELECT employee_id, COUNT(employee_id) AS id_count FROM employees.salary GROUP BY employee_id ORDER BY id_count DESC LIMIT 5;
Result:
| employee_id | id_count |
|---|---|
| 10258 | 18 |
| 10277 | 18 |
| 10137 | 18 |
| 10009 | 18 |
| 10372 | 18 |
The third table is the all-important employees.salary table - it also has a similar relationship with the unique employees.employee table in that there are many-to-one or one-to-many records for each employee and their salary amounts over time.
Let’s also continue to check employee_id 10005’s records for this table ordered by the from_date ascending from earliest to latest to checkout his salary growth over the years with the company:
SELECT * FROM employees.salary WHERE employee_id = 10005;
Result:
| employee_id | amount | from_date | to_date |
|---|---|---|---|
| 10005 | 78228 | 1989-09-12T00:00:00.000Z | 1990-09-12T00:00:00.000Z |
| 10005 | 82621 | 1990-09-12T00:00:00.000Z | 1991-09-12T00:00:00.000Z |
| 10005 | 83735 | 1991-09-12T00:00:00.000Z | 1992-09-11T00:00:00.000Z |
| 10005 | 85572 | 1992-09-11T00:00:00.000Z | 1993-09-11T00:00:00.000Z |
| 10005 | 85076 | 1993-09-11T00:00:00.000Z | 1994-09-11T00:00:00.000Z |
| 10005 | 86050 | 1994-09-11T00:00:00.000Z | 1995-09-11T00:00:00.000Z |
| 10005 | 88448 | 1995-09-11T00:00:00.000Z | 1996-09-10T00:00:00.000Z |
| 10005 | 88063 | 1996-09-10T00:00:00.000Z | 1997-09-10T00:00:00.000Z |
| 10005 | 89724 | 1997-09-10T00:00:00.000Z | 1998-09-10T00:00:00.000Z |
| 10005 | 90392 | 1998-09-10T00:00:00.000Z | 1999-09-10T00:00:00.000Z |
| 10005 | 90531 | 1999-09-10T00:00:00.000Z | 2000-09-09T00:00:00.000Z |
| 10005 | 91453 | 2000-09-09T00:00:00.000Z | 2001-09-09T00:00:00.000Z |
| 10005 | 94692 | 2001-09-09T00:00:00.000Z | 9999-01-01T00:00:00.000Z |
We found out that the same from_date and to_date columns exist in this table, along with it’s arbitrary end date of 9999-01-01 which we will need to deal with later.
⭐ department_employee
We now take a look at the employees.department_employee table which captures information for which department each employee belongs to throughout their career with our company.
SELECT employee_id, COUNT(DISTINCT department_id) AS unique_departments FROM employees.department_employee GROUP BY employee_id ORDER BY unique_departments DESC LIMIT 5;
Result:
| employee_id | unique_departments |
|---|---|
| 10029 | 2 |
| 10040 | 2 |
| 10010 | 2 |
| 10018 | 2 |
| 10050 | 2 |
In the same vain as the previous tables - we have the same slow changing dimension (SCD) style data design with a many-to-one relationship with the base employees.employee table
SELECT * FROM employees.department_employee WHERE employee_id = 10029 LIMIT 5;
Result:
| employee_id | department_id | from_date | to_date |
|---|---|---|---|
| 10029 | d004 | 1991-09-18T00:00:00.000Z | 1999-07-08T00:00:00.000Z |
| 10029 | d006 | 1999-07-08T00:00:00.000Z | 9999-01-01T00:00:00.000Z |
We can see that they’ve changed departments from d004 to d006 on 1999-07-08 (well, we’ll add 18 years to this date later!).
This department_id value is all good and well though - but wouldn’t it be more useful if we were to actually use the department name…
⭐ department_manager
Before we cover the actual department name - let’s also take a look at the department manager too, this time still with the random looking department_id values!
SELECT * FROM employees.department_manager ORDER BY employee_id LIMIT 5;
Result:
| employee_id | department_id | from_date | to_date |
|---|---|---|---|
| 110022 | d001 | 1985-01-01T00:00:00.000Z | 1991-10-01T00:00:00.000Z |
| 110039 | d001 | 1991-10-01T00:00:00.000Z | 9999-01-01T00:00:00.000Z |
| 110085 | d002 | 1985-01-01T00:00:00.000Z | 1989-12-17T00:00:00.000Z |
| 110114 | d002 | 1989-12-17T00:00:00.000Z | 9999-01-01T00:00:00.000Z |
| 110183 | d003 | 1985-01-01T00:00:00.000Z | 1992-03-21T00:00:00.000Z |
In the same way that the employees.department_employee table shows the relationship between employees and their respective departments throughout time - the employees.department_manager table shows the employee_id of the manager of each department throughout time.
To inspect this dataset - how about we take a look at that department_id = 'd004' record:
SELECT * FROM employees.department_manager WHERE department_id = 'd004' ORDER BY from_date;
Result:
| employee_id | department_id | from_date | to_date |
|---|---|---|---|
| 110303 | d004 | 1985-01-01T00:00:00.000Z | 1988-09-09T00:00:00.000Z |
| 110344 | d004 | 1988-09-09T00:00:00.000Z | 1992-08-02T00:00:00.000Z |
| 110386 | d004 | 1992-08-02T00:00:00.000Z | 1996-08-30T00:00:00.000Z |
| 110420 | d004 | 1996-08-30T00:00:00.000Z | 9999-01-01T00:00:00.000Z |
As transparent from the table, we know the current and previous managers of department_id d004 - well at least we know their employee_id, we’ll need to join back onto the employees.employee table to grab out more of their personal details.
⭐ Department table
The employees.department table is just like the employees.employee table where there is a 1:1 unique relationship between the id or department_id and the dept_name.
SELECT * FROM employees.department ORDER BY id;
Result:
| id | dept_name |
|---|---|
| d001 | Marketing |
| d002 | Finance |
| d003 | Human Resources |
| d004 | Production |
| d005 | Development |
| d006 | Quality Management |
| d007 | Sales |
| d008 | Research |
| d009 | Customer Service |
1.3 Updates MATERIALIZED VIEW 🔄
For views which might be accessed multiple times frequently - it makes a lot of sense to create a materialized view as there is only a single REFRESH MATERIALIZED VIEW statement to pull in the new data if there are any changes in the upstream source data.
Additionally - I will create indexes on materialized views which will also get updated whenever we refresh the materialized view.
-- DROP existing schema if it exists DROP SCHEMA IF EXISTS mv_employees CASCADE; CREATE SCHEMA mv_employees; -- department DROP MATERIALIZED VIEW IF EXISTS mv_employees.department; CREATE MATERIALIZED VIEW mv_employees.department AS SELECT * FROM employees.department; -- department employee DROP MATERIALIZED VIEW IF EXISTS mv_employees.department_employee; CREATE MATERIALIZED VIEW mv_employees.department_employee AS SELECT employee_id, department_id, interval '18 years'::DATE AS from_date, CASE WHEN to_date <> '9999-01-01' THEN (to_date + interval '18 years')::DATE ELSE to_date END AS to_date FROM employees.department_employee; -- department manager DROP MATERIALIZED VIEW IF EXISTS mv_employees.department_manager; CREATE MATERIALIZED VIEW mv_employees.department_manager AS SELECT employee_id, department_id, interval '18 years'::DATE AS from_date, CASE WHEN to_date <> '9999-01-01' THEN (to_date + interval '18 years')::DATE ELSE to_date END AS to_date FROM employees.department_manager; -- employee DROP MATERIALIZED VIEW IF EXISTS mv_employees.employee; CREATE MATERIALIZED VIEW mv_employees.employee AS SELECT id, interval '18 years'::DATE AS birth_date, first_name, last_name, gender, interval '18 years'::DATE AS hire_date FROM employees.employee; -- salary DROP MATERIALIZED VIEW IF EXISTS mv_employees.salary; CREATE MATERIALIZED VIEW mv_employees.salary AS SELECT employee_id, amount, interval '18 years'::DATE AS from_date, CASE WHEN to_date <> '9999-01-01' THEN (to_date + interval '18 years')::DATE ELSE to_date END AS to_date FROM employees.salary; -- title DROP MATERIALIZED VIEW IF EXISTS mv_employees.title; CREATE MATERIALIZED VIEW mv_employees.title AS SELECT employee_id, title, interval '18 years'::DATE AS from_date, CASE WHEN to_date <> '9999-01-01' THEN (to_date + interval '18 years')::DATE ELSE to_date END AS to_date FROM employees.title; -- Index Creation -- NOTE: we do not name the indexes as they will be given randomly upon creation! CREATE UNIQUE INDEX ON mv_employees.employee USING btree (id); CREATE UNIQUE INDEX ON mv_employees.department_employee USING btree (employee_id, department_id); CREATE INDEX ON mv_employees.department_employee USING btree (department_id); CREATE UNIQUE INDEX ON mv_employees.department USING btree (id); CREATE UNIQUE INDEX ON mv_employees.department USING btree (dept_name); CREATE UNIQUE INDEX ON mv_employees.department_manager USING btree (employee_id, department_id); CREATE INDEX ON mv_employees.department_manager USING btree (department_id); CREATE UNIQUE INDEX ON mv_employees.salary USING btree (employee_id, from_date); CREATE UNIQUE INDEX ON mv_employees.title USING btree (employee_id, title, from_date);
2. Problem Solving 💡
📊 Required Insights for HR Analytica Dashboards
🏢 Company Level Insights:
- Snapshot of Total Employees: Include a gender-specific breakdown.
- Average Tenure: How long employees typically remain at the company.
- Latest Payrise Percentage: Average increase in pay across the company.
- Salary Metrics: Include minimum, maximum, standard deviation, inter-quartile range, and median.
📁 Department Level Insights:
- Department-specific Metrics: Tailored insights similar to company level but broken down by department.
- Tenure Analysis: Analyze average tenure within each department, segmented by gender.
🏷️ Title Level Insights:
- Granular Title Insights: Provide count and average tenure for each title, mirroring department level detail.
🔍 Employee Deep Dive:
- Historical Employment Changes: Review chronological employment changes, including salary adjustments, department shifts, and title changes.
- Payrise History: Calculate percentages and value changes in past pay rises.
- Position and Department Tenure: Examine durations of past roles with start and end dates.
- Comparison to Benchmarks: Compare an employee’s current salary, tenure, department, and position against average benchmarks.
2.1 Solution for the Case Study 💡
This is the final script for the problem solution of this case study:
/*----------------------------------- Current employee snapshot view -------------------------------------*/ DROP VIEW IF EXISTS mv_employees.current_employee_snapshot; CREATE VIEW mv_employees.current_employee_snapshot AS WITH cte_previous_salary AS ( SELECT * FROM ( SELECT employee_id, to_date, LAG(amount) OVER ( PARTITION BY employee_id ORDER BY from_date ) AS amount FROM mv_employees.salary ) all_salaries WHERE to_date = '9999-01-01' ), cte_joined_data AS ( SELECT employee.id AS employee_id, CONCAT_WS(' ', employee.first_name, employee.last_name) AS employee_name, employee.gender, employee.hire_date, title.title, salary.amount AS salary, cte_previous_salary.amount AS previous_salary, department.dept_name AS department, CONCAT_WS(' ', manager.first_name, manager.last_name) AS manager, title.from_date AS title_from_date, department_employee.from_date AS department_from_date FROM mv_employees.employee INNER JOIN mv_employees.title ON employee.id = title.employee_id INNER JOIN mv_employees.salary ON employee.id = salary.employee_id INNER JOIN cte_previous_salary ON employee.id = cte_previous_salary.employee_id INNER JOIN mv_employees.department_employee ON employee.id = department_employee.employee_id INNER JOIN mv_employees.department ON department_employee.department_id = department.id INNER JOIN mv_employees.department_manager ON department.id = department_manager.department_id INNER JOIN mv_employees.employee AS manager ON department_manager.employee_id = manager.id WHERE salary.to_date = '9999-01-01' AND title.to_date = '9999-01-01' AND department_employee.to_date = '9999-01-01' AND department_manager.to_date = '9999-01-01' ) SELECT employee_id, employee_name, manager, gender, title, salary, department, -- salary change percentage ROUND( 100 * (salary - previous_salary) / previous_salary::NUMERIC, 2 ) AS salary_percentage_change, -- tenure calculations DATE_PART('year', now()) - DATE_PART('year', hire_date) AS company_tenure_years, DATE_PART('year', now()) - DATE_PART('year', title_from_date) AS title_tenure_years, DATE_PART('year', now()) - DATE_PART('year', department_from_date) AS department_tenure_years FROM cte_joined_data; /*--------------------------- Aggregated dashboard views -----------------------------*/ -- company level aggregation view DROP VIEW IF EXISTS mv_employees.company_level_dashboard; CREATE VIEW mv_employees.company_level_dashboard AS SELECT gender, COUNT(*) AS employee_count, ROUND(100 * COUNT(*)::NUMERIC / SUM(COUNT(*)) OVER ()) AS employee_percentage, ROUND(AVG(company_tenure_years)) AS company_tenure, ROUND(AVG(salary)) AS avg_salary, ROUND(AVG(salary_percentage_change)) AS avg_salary_percentage_change, -- salary statistics ROUND(MIN(salary)) AS min_salary, ROUND(MAX(salary)) AS max_salary, ROUND( PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY salary)) AS median_salary, ROUND( PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY salary) - PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY salary) ) AS inter_quartile_range, ROUND(STDDEV(salary)) AS stddev_salary FROM mv_employees.current_employee_snapshot GROUP BY gender; -- department level aggregation view DROP VIEW IF EXISTS mv_employees.department_level_dashboard; CREATE VIEW mv_employees.department_level_dashboard AS SELECT gender, department, COUNT(*) AS employee_count, ROUND(100 * COUNT(*)::NUMERIC / SUM(COUNT(*)) OVER ( PARTITION BY department )) AS employee_percentage, ROUND(AVG(department_tenure_years)) AS department_tenure, ROUND(AVG(salary)) AS avg_salary, ROUND(AVG(salary_percentage_change)) AS avg_salary_percentage_change, -- salary statistics ROUND(MIN(salary)) AS min_salary, ROUND(MAX(salary)) AS max_salary, ROUND( PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY salary)) AS median_salary, ROUND( PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY salary) - PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY salary) ) AS inter_quartile_range, ROUND(STDDEV(salary)) AS stddev_salary FROM mv_employees.current_employee_snapshot GROUP BY gender, department; -- title level aggregation view DROP VIEW IF EXISTS mv_employees.title_level_dashboard; CREATE VIEW mv_employees.title_level_dashboard AS SELECT gender, title, COUNT(*) AS employee_count, ROUND(100 * COUNT(*)::NUMERIC / SUM(COUNT(*)) OVER ( PARTITION BY title )) AS employee_percentage, ROUND(AVG(title_tenure_years)) AS title_tenure, ROUND(AVG(salary)) AS avg_salary, ROUND(AVG(salary_percentage_change)) AS avg_salary_percentage_change, -- salary statistics ROUND(MIN(salary)) AS min_salary, ROUND(MAX(salary)) AS max_salary, ROUND( PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY salary)) AS median_salary, ROUND( PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY salary) - PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY salary) ) AS inter_quartile_range, ROUND(STDDEV(salary)) AS stddev_salary FROM mv_employees.current_employee_snapshot GROUP BY gender, title; /*----------------------- Salary Benchmark Views -------------------------*/ DROP VIEW IF EXISTS mv_employees.tenure_benchmark; CREATE VIEW mv_employees.tenure_benchmark AS SELECT company_tenure_years, AVG(salary) AS tenure_benchmark_salary FROM mv_employees.current_employee_snapshot GROUP BY company_tenure_years; DROP VIEW IF EXISTS mv_employees.gender_benchmark; CREATE VIEW mv_employees.gender_benchmark AS SELECT gender, AVG(salary) AS gender_benchmark_salary FROM mv_employees.current_employee_snapshot GROUP BY gender; DROP VIEW IF EXISTS mv_employees.department_benchmark; CREATE VIEW mv_employees.department_benchmark AS SELECT department, AVG(salary) AS department_benchmark_salary FROM mv_employees.current_employee_snapshot GROUP BY department; DROP VIEW IF EXISTS mv_employees.title_benchmark; CREATE VIEW mv_employees.title_benchmark AS SELECT title, AVG(salary) AS title_benchmark_salary FROM mv_employees.current_employee_snapshot GROUP BY title; /*---------------------------------- 1. Historic Employee Deep Dive View -----------------------------------*/ DROP VIEW IF EXISTS mv_employees.historic_employee_records CASCADE; CREATE VIEW mv_employees.historic_employee_records AS WITH cte_previous_salary AS ( SELECT employee_id, amount FROM ( SELECT employee_id, to_date, LAG(amount) OVER ( PARTITION BY employee_id ORDER BY from_date ) AS amount, ROW_NUMBER() OVER ( PARTITION BY employee_id ORDER BY to_date DESC ) AS record_rank FROM mv_employees.salary ) all_salaries WHERE record_rank = 1 ), cte_join_data AS ( SELECT employee.id AS employee_id, employee.birth_date, -- calculated employee_age field DATE_PART('year', now()) - DATE_PART('year', employee.birth_date) AS employee_age, -- employee full name CONCAT_WS(' ', employee.first_name, employee.last_name) AS employee_name, employee.gender, employee.hire_date, title.title, salary.amount AS salary, cte_previous_salary.amount AS previous_latest_salary, department.dept_name AS department, -- use the `manager` aliased version of employee table for manager CONCAT_WS(' ', manager.first_name, manager.last_name) AS manager, -- calculated tenure fields DATE_PART('year', now()) - DATE_PART('year', employee.hire_date) AS company_tenure_years, DATE_PART('year', now()) - DATE_PART('year', title.from_date) AS title_tenure_years, DATE_PART('year', now()) - DATE_PART('year', department_employee.from_date) AS department_tenure_years, -- we also need to use AGE & DATE_PART functions here to generate month diff DATE_PART('months', AGE(now(), title.from_date)) AS title_tenure_months, GREATEST( title.from_date, salary.from_date, department_employee.from_date, department_manager.from_date ) AS effective_date, LEAST( title.to_date, salary.to_date, department_employee.to_date, department_manager.to_date ) AS expiry_date FROM mv_employees.employee INNER JOIN mv_employees.title ON employee.id = title.employee_id INNER JOIN mv_employees.salary ON employee.id = salary.employee_id INNER JOIN mv_employees.department_employee ON employee.id = department_employee.employee_id INNER JOIN mv_employees.department ON department_employee.department_id = department.id INNER JOIN mv_employees.department_manager ON department.id = department_manager.department_id INNER JOIN mv_employees.employee AS manager ON department_manager.employee_id = manager.id INNER JOIN cte_previous_salary ON mv_employees.employee.id = cte_previous_salary.employee_id ), cte_ordered_transactions AS ( SELECT employee_id, birth_date, employee_age, employee_name, gender, hire_date, title, LAG(title) OVER w AS previous_title, salary, previous_latest_salary, LAG(salary) OVER w AS previous_salary, department, LAG(department) OVER w AS previous_department, manager, LAG(manager) OVER w AS previous_manager, company_tenure_years, title_tenure_years, title_tenure_months, department_tenure_years, effective_date, expiry_date, ROW_NUMBER() OVER ( PARTITION BY employee_id ORDER BY effective_date DESC ) AS event_order FROM cte_join_data WHERE effective_date <= expiry_date WINDOW w AS (PARTITION BY employee_id ORDER BY effective_date) ), final_output AS ( SELECT base.employee_id, base.gender, base.birth_date, base.employee_age, base.hire_date, base.title, base.employee_name, base.previous_title, base.salary, previous_latest_salary, base.previous_salary, base.department, base.previous_department, base.manager, base.previous_manager, -- tenure metrics base.company_tenure_years, base.title_tenure_years, base.title_tenure_months, base.department_tenure_years, base.event_order, CASE WHEN event_order = 1 THEN ROUND( 100 * (base.salary - base.previous_latest_salary) / base.previous_latest_salary::NUMERIC, 2 ) ELSE NULL END AS latest_salary_percentage_change, CASE WHEN event_order = 1 THEN ROUND( base.salary - base.previous_latest_salary ) ELSE NULL END AS latest_salary_amount_change, CASE WHEN base.previous_salary < base.salary THEN 'Salary Increase' WHEN base.previous_salary > base.salary THEN 'Salary Decrease' WHEN base.previous_department <> base.department THEN 'Dept Transfer' WHEN base.previous_manager <> base.manager THEN 'Reporting Line Change' WHEN base.previous_title <> base.title THEN 'Title Change' ELSE NULL END AS event_name, -- salary change ROUND(base.salary - base.previous_salary) AS salary_amount_change, ROUND( 100 * (base.salary - base.previous_salary) / base.previous_salary::NUMERIC, 2 ) AS salary_percentage_change, -- tenure ROUND(tenure_benchmark_salary) AS tenure_benchmark_salary, ROUND( 100 * (base.salary - tenure_benchmark_salary) / tenure_benchmark_salary::NUMERIC ) AS tenure_comparison, -- title ROUND(title_benchmark_salary) AS title_benchmark_salary, ROUND( 100 * (base.salary - title_benchmark_salary) / title_benchmark_salary::NUMERIC ) AS title_comparison, -- department ROUND(department_benchmark_salary) AS department_benchmark_salary, ROUND( 100 * (salary - department_benchmark_salary) / department_benchmark_salary::NUMERIC ) AS department_comparison, -- gender ROUND(gender_benchmark_salary) AS gender_benchmark_salary, ROUND( 100 * (base.salary - gender_benchmark_salary) / gender_benchmark_salary::NUMERIC ) AS gender_comparison, base.effective_date, base.expiry_date FROM cte_ordered_transactions AS base INNER JOIN mv_employees.tenure_benchmark ON base.company_tenure_years = tenure_benchmark.company_tenure_years INNER JOIN mv_employees.title_benchmark ON base.title = title_benchmark.title INNER JOIN mv_employees.department_benchmark ON base.department = department_benchmark.department INNER JOIN mv_employees.gender_benchmark ON base.gender = gender_benchmark.gender ) SELECT * FROM final_output; -- by keeping only the 5 latest events DROP VIEW IF EXISTS mv_employees.employee_deep_dive; CREATE VIEW mv_employees.employee_deep_dive AS SELECT * FROM mv_employees.historic_employee_records WHERE event_order <= 5;
2.2 Results 📊
⭐ Department Level Results
SELECT * FROM mv_employees.department_level_dashboard ORDER BY department, gender;
Results:
| gender | department | employee_count | employee_percentage | department_tenure | avg_salary | avg_salary_percentage_change | min_salary | max_salary | median_salary | inter_quartile_range | stddev_salary |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M | Customer Service | 10562 | 60 | 9 | 67203 | 3 | 39373 | 143950 | 65100 | 20097 | 15921 |
| F | Customer Service | 7007 | 40 | 9 | 67409 | 3 | 39812 | 144866 | 65198 | 20450 | 15979 |
| M | Development | 36853 | 60 | 11 | 67713 | 3 | 39036 | 140784 | 66526 | 19664 | 14267 |
| F | Development | 24533 | 40 | 11 | 67576 | 3 | 39469 | 144434 | 66355 | 19309 | 14149 |
| M | Finance | 7423 | 60 | 11 | 78433 | 3 | 39012 | 142395 | 77526 | 24078 | 17242 |
| F | Finance | 5014 | 40 | 11 | 78747 | 3 | 39949 | 136978 | 78285 | 23576 | 16833 |
| M | Human Resources | 7751 | 60 | 11 | 63777 | 3 | 39611 | 141953 | 62864 | 17607 | 12843 |
| F | Human Resources | 5147 | 40 | 11 | 64140 | 3 | 38936 | 123268 | 62782 | 17674 | 12955 |
| M | Marketing | 8978 | 60 | 10 | 80293 | 3 | 39821 | 145128 | 79481 | 24990 | 17480 |
| F | Marketing | 5864 | 40 | 10 | 79700 | 3 | 39871 | 141842 | 78596 | 24512 | 17293 |
| M | Production | 31911 | 60 | 10 | 67921 | 3 | 38623 | 132552 | 66768 | 19662 | 14271 |
| F | Production | 21393 | 40 | 10 | 67728 | 3 | 39476 | 138273 | 66645 | 19485 | 14099 |
| M | Quality Management | 8674 | 60 | 10 | 65361 | 3 | 38942 | 132103 | 64258 | 18465 | 13402 |
| F | Quality Management | 5872 | 40 | 10 | 65562 | 3 | 39571 | 122965 | 64685 | 18386 | 13259 |
| M | Research | 9260 | 60 | 10 | 67848 | 3 | 39186 | 130211 | 66576 | 19749 | 14435 |
| F | Research | 6181 | 40 | 10 | 68012 | 3 | 39526 | 124158 | 66814 | 19100 | 14252 |
| M | Sales | 22702 | 60 | 11 | 88864 | 2 | 39426 | 158220 | 88462 | 24401 | 17757 |
| F | Sales | 14999 | 40 | 11 | 88836 | 2 | 40392 | 152710 | 88581 | 24712 | 17738 |
⭐ Title Level Results
SELECT * FROM mv_employees.title_level_dashboard ORDER BY title, gender;
Results:
| Gender | Title | Employee Count | Employee Percentage | Title Tenure | Avg Salary | Avg Salary Percentage Change | Min Salary | Max Salary | Median Salary | Inter Quartile Range | Stddev Salary |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M | Assistant Engineer | 2148 | 60 | 6 | 57198 | 4 | 39827 | 117636 | 54384 | 14972 | 11152 |
| F | Assistant Engineer | 1440 | 40 | 6 | 57496 | 4 | 39469 | 106340 | 55234 | 14679 | 10805 |
| M | Engineer | 18571 | 60 | 6 | 59593 | 4 | 38942 | 130939 | 56941 | 17311 | 12416 |
| F | Engineer | 12412 | 40 | 6 | 59617 | 4 | 39519 | 115444 | 57220 | 17223 | 12211 |
| M | Manager | 5 | 56 | 9 | 79351 | 2 | 56654 | 106491 | 72876 | 43242 | 23615 |
| F | Manager | 4 | 44 | 12 | 75690 | 3 | 65400 | 83457 | 76952 | 8176 | 7774 |
| M | Senior Engineer | 51533 | 60 | 7 | 70870 | 3 | 39285 | 140784 | 69509 | 18081 | 13596 |
| F | Senior Engineer | 34406 | 40 | 8 | 70754 | 3 | 39476 | 138273 | 69478 | 17918 | 13494 |
| M | Senior Staff | 49232 | 60 | 7 | 80735 | 3 | 39012 | 158220 | 78704 | 27310 | 18679 |
| F | Senior Staff | 32792 | 40 | 7 | 80663 | 3 | 39227 | 152710 | 78617 | 27406 | 18621 |
| M | Staff | 15436 | 60 | 6 | 67362 | 3 | 39186 | 133577 | 65120 | 27388 | 17193 |
| F | Staff | 10090 | 40 | 6 | 67282 | 3 | 38936 | 137875 | 65110 | 26470 | 16815 |
| M | Technique Leader | 7189 | 60 | 11 | 67600 | 3 | 38623 | 132233 | 66558 | 19162 | 14087 |
| F | Technique Leader | 4866 | 40 | 11 | 67369 | 3 | 39812 | 144434 | 66174 | 18710 | 13939 |
⭐ Salary Benchmark Results
1.Company Tenure Benchmark
SELECT * FROM mv_employees.tenure_benchmark ORDER BY company_tenure_years;
Results:
| company_tenure_years | tenure_benchmark_salary |
| 3 | 58192.111111111111 |
| 4 | 58199.38122923588 |
| 5 | 5880559673.06020469 |
| 6 | 5966660794.59939531 |
| 7 | 3681762424.67458556 |
| 8 | 3242863705.12614184 |
| 9 | 5427965332.55085387 |
| 10 | 39801067090.80016693 |
| 11 | 32961168286.07106038 |
| 12 | 29161269812.80344427 |
| 13 | 88541371483.85741547 |
| 14 | 19381473053.44542307 |
| 15 | 52381574201.56035477 |
| 16 | 07121675927.58821765 |
| 17 | 85221777411.44632454 |
| 18 | 92371878870.31624898 |
2. Gender Benchmark
SELECT * FROM mv_employees.gender_benchmark;
Results:
| gender | gender_benchmark_salary |
| M | 72044.656972951969 |
| F | 71963.570753046558 |
3. Department Benchmark
SELECT * FROM mv_employees.department_benchmark ORDER BY department_benchmark_salary DESC;
Results:
| department | department_benchmark_salary |
| Sales | 88852.969470305827 |
| Marketing | 80058.848807438351 |
| Finance | 78559.936962289941 |
| Research | 67913.374975714008 |
| Production | 67843.301984841663 |
| Development | 67657.919558205454 |
| Customer Service | 67285.230178154704 |
| Quality Management | 65441.993400247491 |
| Human Resources | 63921.899829430920 |
4. Title Benchmark
SELECT * FROM mv_employees.title_benchmark ORDER BY title_benchmark_salary DESC;
Results:
| title | title_benchmark_salary |
| Senior Staff | 80706.495879254852 |
| Manager | 77723.666666666667 |
| Senior Engineer | 70823.437647633787 |
| Technique Leader | 67506.590294483617 |
| Staff | 67330.665204105618 |
| Engineer | 59602.737759416454 |
| Assistant Engineer | 57317.573578595318 |
⭐ Historic Employee Deep Dive Example
SELECT * FROM mv_employees.employee_deep_dive WHERE employee_name = 'Leah Anguita' ORDER BY event_order;
Results:
| employee_id | gender | birth_date | employee_age | hire_date | title | employee_name | previous_title | salary | previous_latest_salary | previous_salary | department | previous_department | manager | previous_manager | company_tenure_years | title_tenure_years | title_tenure_months | department_tenure_years | event_order | latest_salary_percentage_change | event_name | salary_amount_change | salary_percentage_change | tenure_benchmark_salary | tenure_comparison | title_benchmark_salary | title_comparison | department_benchmark_salary | department_comparison | gender_benchmark_salary | gender_comparison | effective_date | expiry_date |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11669 | M | 3/3/1975 | 46 | 4/7/2004 | Senior Engineer | Leah Anguita | Engineer | 47373 | 47046 | 47373 | Customer Service | Customer Service | Yuchang Weedman | Yuchang Weedman | 17 | 1 | 1 | 12 | 10 | 0.7 | Title Change | 0 | 77411-39 | 70823-33 | 67285-30 | 72045-34 | 5/12/2020 | 1/1/9999 | |||||
| 11669 | M | 3/3/1975 | 46 | 4/7/2004 | Engineer | Leah Anguita | Engineer | 47373 | 47046 | 47046 | Customer Service | Customer Service | Yuchang Weedman | Yuchang Weedman | 17 | 6 | 1 | 12 | 2 | 0.7 | Salary Increase | 3270 | 77411-39 | 59603-21 | 67285-30 | 72045-34 | 5/11/2020 | 5/12/2020 | |||||
| 11669 | M | 3/3/1975 | 46 | 4/7/2004 | Engineer | Leah Anguita | Engineer | 47046 | 47046 | 47046 | Customer Service | Production | Yuchang Weedman | Oscar Ghazalie | 17 | 6 | 1 | 12 | 3 | 0 | Dept Transfer | 0 | 77411-39 | 59603-21 | 67285-30 | 72045-35 | 6/12/2019 | 5/11/2020 | |||||
| 11669 | M | 3/3/1975 | 46 | 4/7/2004 | Engineer | Leah Anguita | Engineer | 47046 | 47046 | 43681 | Production | Production | Oscar Ghazalie | Oscar Ghazalie | 17 | 6 | 1 | 1 | 6 | 7.7 | Salary Increase | 3365 | 77411-39 | 59603-21 | 67843-31 | 72045-35 | 5/11/2019 | 6/12/2019 | |||||
| 11669 | M | 3/3/1975 | 46 | 4/7/2004 | Engineer | Leah Anguita | Engineer | 43681 | 47046 | 43930 | Production | Production | Oscar Ghazalie | Oscar Ghazalie | 17 | 6 | 1 | 1 | 6 | -0.5 | Salary Decrease | -249 | 777411-44 | 59603-27 | 67843-36 | 72045-39 | 5/11/2018 | 5/11/2019 |
3. Visualization on Tableau 📈
Following the comprehensive data preparation process, we utilize Tableau to construct an insightful HR dashboard.
